Nội dung bài viết
Khi bọ tìm kiếm tìm đến website của bạn, bạn có quyền điều khiển hoạt động của chúng. Trên website của bạn có những nội dung chưa đầy đủ hoặc nội dung riêng tư mà bạn không muốn người khác biết đến. Bạn có thể chặn không cho bọ tìm kiếm tìm đến những nội dung này.
Có 2 công cụ có thể giúp bạn làm điều này:
1. File Robots.txt: Cần được đặt trong thư mục gốc để phát huy tác dụng, dung để chặn bọ tìm kiếm không cho chúng truy cập vào một hoặc nhiều trang web nào đó.
Có thể tham khảo thêm Chuẩn mới kết quả tìm kiếm
2. Thẻ Meta Robots: Đặt trong phần head của 1 trang web và điều khiển cách bọ tìm kiếm tương tác với nội dung cũng như cách hiển thị trang web trên kết quả tìm kiếm
Dưới đây là những ưu, nhược điểm của 2 phương pháp kể trên.
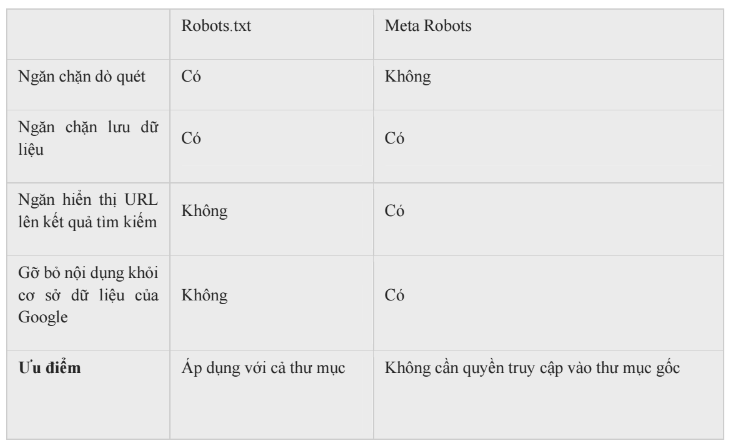
Các loại lệnh
Robots.txt:
Sử dụng file robots.txt để điều khiển truy cập vào các files và các thư mục trong website của bạn. File này hoạt động giống như một biển báo giao thông. Nó báo với Googlebot và các con bọ tìm kiếm khác những file và thư mục trên website của bạn mà không được dò quét. Để sử dụng file robots.txt, bạn phải có quyền truy cập vào thư mục gốc của website. Nếu bạn không thể truy cập vào thư mục gốc, bạn cũng có thể điều khiển truy cập của bọ tìm kiếm bằng cách sử dụng thẻ meta robots trên từng trang riêng lẻ.
Tuy nhiên, hãy nhớ rằng, kể cả khi bạn sử dụng file robots.txt để chặn bọ tìm kiếm truy cập vào nội dung của bạn, Google vẫn có thể khám phá ra nội dung của bạn và đưa nó vào bảng kết quả tìm kiếm nhờ những cách khác. Ví dụ, thông qua đường link mà các trang web khác trỏ đến trang web đó. Kết quả là, địa chỉ URL của các trang web cũng như văn bản neo của các lien kết trỏ đến các trang web này có thể xuất hiện trong bảng kết quả tìm kiếm. Thêm vào đó, trong khi bọ tìm kiếm của các công cụ tìm kiếm lớn đều tôn trọng chỉ dẫn trong file robots.txt, một vài bọ tìm kiếm khác thì không. Vì file robots.txt chỉ là bảng chỉ dẫn, nên những người có mục đích xấu hoàn toàn có thể bỏ qua chúng và vẫn dò quét nội dung website như thường. Vì lý do này, theo chúng tôi cách an toàn nhất là đặt password bảo vệ cho các file hoặc thư mục này Bạn nên sử dụng file này khi muốn ngăn bọ tìm kiếm dò quét một trang web hoặc toàn bộ website.
Và do đó, trang web cũng không bị lưu vào cơ sở dữ liệu của máy tìm kiếm. Nhưng bạn không thể sử dụng phương pháp này để gỡ bỏ trang web khỏi CSDL của máy tìm kiếm khi nó đã được lưu vào từ trước. File Robots.txt có thể ngăn chặn truy cập đến cả một thư mục hoặc đến một trang web cụ thể. Cách này cũng hay được sử dụng để ngăn chặn bọ tìm kiếm truy cập vào các file không thuộc định dạng HTML như hình ảnh, file PDFs, file Microsoft Office…
Meta robots –
Chèn thuộc tính “noindex” vào thẻ meta robots để ngăn chặn nội dung xuất hiện trên bảng kết quả tìm kiếm. Khi bọ tìm kiếm nhìn thấy thuộc tính “noindex” trên một trang web, Google bỏ qua trang web đó không đưa nó lên bảng kết quả tìm kiếm, kể cả khi có các trang web khác trỏ link tới nó. Còn nếu nội dung đã tồn tại trong CSDL của Google, họ sẽ gỡ bỏ hoàn toàn những nội dung này. Chú ý, với các máy tìm kiếm khác không phải là Google, tác dụng của thẻ meta này sẽ có khác biệt
Lưu ý, vì Google phải dò quét trang web của bạn thì mới biết được trong đó có thẻ meta robots không và nội dung của nó cụ thể như thế nào, có thể xảy ra trường hợp là bạn đã cài đặt thuộc tính noindex trong thẻ meta robots nhưng trang web vẫn xuất hiện trong bảng kết quả tìm kiếm. Điều này là do bọ tìm kiếm chưa quay lại dò quét trang web của bạn kể từ khi bạn cập nhật nội dung thẻ meta robots. Cách tạo file Robots.txt File robots.txt nằm trong thư mục gốc ở website hoặc trong subdomain.
Khi viết file robots.txt, việc đầu tiên là xác định rõ nó sẽ nhắm tới loại bọ tìm kiếm nào? Hay loại bọ tìm kiếm nào sẽ phải tuân theo chỉ dẫn trong file này. Đó có thể là Googlebot (của Google), hoặc bọ của những công cụ tìm kiếm khác. Sau khi biết rõ mục tiêu, việc tiếp theo là xác định những nơi nào trên website mà bọ tìm kiếm không được chào đón. Việc này thực hiện bằng cách liệt kê tất cả những thư mục, những trang web mà con bọ không được truy cập vào.
Bên cạnh đó, trong file này bạn cũng nên chỉ rõ vị trí của sơ đồ website XML, để máy tìm kiếm có thể dễ dàng tìm tới nó, từ đó nó dễ dàng dò quét toàn bộ website của bạn.
Dưới đây là ví dụ của 1 file robots.txt:
user-agent: * (Có thể là googlebot, Bingbot, Baiduspider…)
Disallow: /register.html
Disallow: /assets/
Disallow: /category/
Sitemap: http://tiepthi-tructuyen.com/Sitemap.xml
Cách sử dụng thẻ Meta Robots
Bạn chèn thẻ meta robots vào trong phần <head> (là phần mở đầu của mỗi trang web). Dưới đây là ví dụ về một thẻ meta robots
<meta name=”robots” content=”COMMAND”>
Dưới đây là danh sách các câu lệnh thường được sử dụng trong thẻ meta robots
1. index – Trang này cần được index. Mặc định mọi trang web đều được index, nên câu lệnh này là không cần thiết.
2. noindex – Không index trang này, hoặc gỡ bỏ nó khỏi CSDL nếu nó đã được index
3. follow – Khuyến khích máy tìm kiếm đi theo tất cả links trên trang này, Mặc định máy tìm kiếm đã làm việc này, nên câu lệnh này không cần thiết
4. nofollow – Không khuyến khích máy tìm kiếm đi theo bất kỳ links nào trên trang này
5. noarchive – Yêu cầu máy tìm kiếm không được show bản cache của trang web trên bảng kết quả. Câu lệnh này rất ít khi được sử dụng
6. nosnippet – Yêu cầu máy tìm kiếm không được hiển thị thông tin miêu tả về trang trên bảng kết quả
Dưới đây là ví dụ về một thẻ meta robots
<meta name=”robots” content=”noindex,follow”>